We’ve previously written about our journey towards practicing continuous delivery. Most recently, we wrote about Blazing fast builds with buildkite which outlines our efforts towards achieving fast build times. We’ve also talked about CI for more than just unit and integration tests and effective code reviews. Today, we’ll be taking a closer look at the strategies and challenges of shipping code continuously.
During Handshake’s earlier years, we used to deploy to production once-per-week. Like many engineering teams around our size, we faced the dreaded weekly feature freeze: we merged everything to master and let a week’s worth of changes accumulate. Then, once a week on Tuesday afternoons we critique, QA, and release everything at once. Since we had a weekly release cadence, it wasn’t surprising for everyone to merge their changes in at the last hour, otherwise engineers would have to wait a week to deploy again. This created a lot of anxiety around each deployment.
Once our latest changes were deployed it was common for unexpected errors to arise on production. Our automated test suite would fail to cover edge cases bugs found by our customers on production. Since we often deployed the week’s worth of changes in the evening — to minimize customer impact — we had trouble identifying which change caused the problem.
The main reason we took this approach is because we felt it was important to minimize disruption to our customers during the day. Handshake is the primary tool that our customers rely on for their full-time jobs. Unexpected changes in behavior, or showstopper bugs in the middle of the day are unacceptable.
Continuous Delivery
We knew we wanted to achieve continuous delivery, but we also knew we had a few obstacles to overcome before we could get there: First, we needed to separate deployments from feature releases through feature toggles. Our test suite had to remain strong, reliable, and fast. Deployments had to be fully automated. We needed to improve observability in order to surface where and when issues came up. And finally, we needed to coordinate deployments across the team.
Don’t Surprise Our Customers
Handshake is a critical piece of software which our customers rely on every day. Universities use Handshake to operate their career centers with activities like running career fairs, organizing campus interviews, scheduling appointments with advisors, and managing employer relations. And of course, employers and students rely on us for those same functionalities and more.
As it was clear to us that deployments should not change features for every customer on our platform, we began to develop feature toggle infrastructure. Early on we adopted open source libraries such as rollout. This worked well initially, but as we scaled two main problems surfaced.
First, the open source solutions we evaluated didn’t have an easy to use, non-technical interface to change the rollout parameters. This made it hard to product managers and designers to change the parameters of a rollout without going through an engineer. Second, we needed a more performant solution. All open source solutions we found made constant network calls to the caching tier, and on pages with lots of toggles that added up quickly.
To solve these problems we landed on LaunchDarkly. In addition to nice features like assigning features to users, and both A/B and multivariate testing, LaunchDarkly provides a great user interface for managing features and rollouts. Their RubyGem also keeps network performance in mind, by caching toggle states locally.
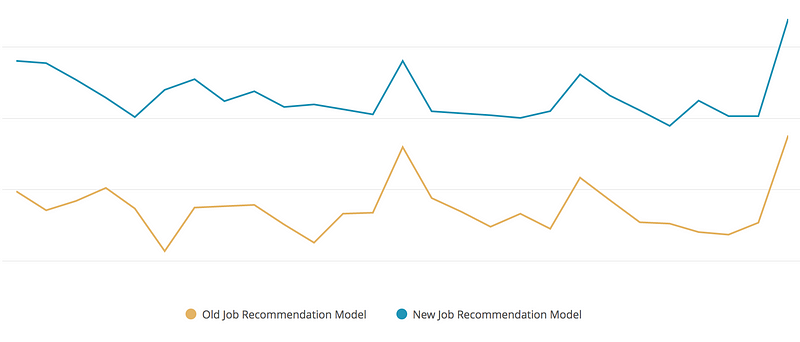
Metrics from a feature toggle enabling a new job recommendations model which shows nearly double engagement.
With some added developer tooling on top of Launchdarkly, using feature toggles quickly became easy and delightful to use while also fundamentally changing the way we build features. Rather than big, feature-complete Pull Requests we can build new features piece by piece behind a feature toggle with small, easy to review Pull Requests.
In addition, once the feature is complete we can roll out to only a percentage of beta users first and watch for errors, feedback, and metrics to see the impact the change made.
Robust test suite
Having a robust test suite from the beginning has been an important part of being able to move quickly and confidently. However, moving to continuous delivery adds even more emphasis on a reliable and fast test suite. Blazing fast builds with buildkite has great details on how our team does continuous integration.
Smooth code deployment to web servers
If we’re going to deploy throughout the day, we can’t have any service interruptions during those deploys. Response time should be consistent and downtime non-existent during deploys. There were a few steps we took to guarantee smooth deploys.
In our experience database migrations during deploys have been one of the main contributors to downtime or elevated error rates. One of the most positive impacts on preventing database migration issues for us has been adopting strong_migrations. Put simply, we decouple database schema changes from the code changes that rely on that change. If the User model needs a new field, we’ll stage the changes into two commits. The first commit adds the column using a Rails migration. Once that completes, we’ll deploy a second commit containing code which uses the new column.
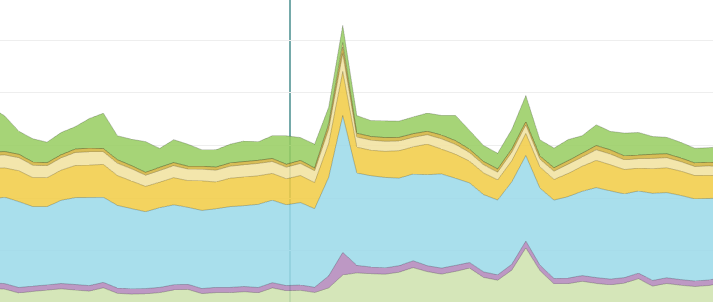
Every deployment is recorded in our APM, shown here by a vertical line.
We’ve also implemented database query and lock timeouts. These ensure that if a database migration has mistakenly acquired a lock that may impact other parts of the application, the migration will quickly fail and we can fix the migration. For more information on this topic, we recently wrote about PostgreSQL and its Lock Queue.
Lastly — The preboot feature on Heroku is a must for any high scale application hosted on Heroku. Preboot allows you to run your old code for a few minutes before switching to the new code to ensure that the new code is ready to take traffic. Although it imposes some requirements on how your organization deploys code (most notably, separating database schema changes from the code usage as mentioned previously) it ensures a relatively smooth deploy for the web dynos. Not to mention that the alternative on Heroku — hard restart — is not acceptable at scale.
Fully Automated Deployments
Continuous delivery requires one-click deploys. Although we had one-click (or, at least, one console command) from early on we are happy to have adopted Shipit-engine from Shopify. “Shipit” has given us a few key functionalities.
One of those improvements are deployment coordinations. Before we started using Shipit, it would have been possible for two people to deploy from their local machine at the same time. This was unlikely early on with only a few engineers, but as the engineering team grew that was no longer the case. Shipit informs us when someone else is doing a deploy or even when they are _planning_to do a deploy. We do this both through UI indicators and with Slack integrations to our #deployments channel. The ability to coordinate deploys prevents any issues with double deploys.
Using a Web UI to coordinate deploys also gives us better visibility into what our deployment behavior looks like. At a glance we can see what is undeployed in master, what the previous deployment timeline looks like, and deployment logs. With first class GitHub integrations, we can also see whether or not the build has passed for each commit in master, what the diff for the deploy is, and who authored the change.
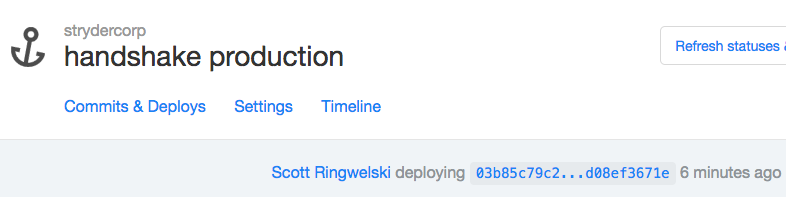
A glance at our deployer app on a deployment page. From here we can view the status of commits, deployment timeline, and the deployment logs.
We also can make programmatic additions on top of our deployment app. For example, we are working towards being able to lock deployments (a feature also on the web UI), initiate deploys, and log deployment progress all in Slack.
Team Coordination
Moving from weekly deploys to multiple per day to continuous requires a mindshift from the whole team. It fundamentally changes the way our company thinks about shipping features. And, especially in engineering, how features are written. There is no longer a weekly race to get your full features merged — the process now calls for small incremental improvements safely guarded behind feature flags.
Observability
With the once-per-week deployment process, our primary defense against bugs was prevention. Once everything was merged we did heavy manual QA (in addition to our automated tests) which often took a long time to cover every change.
With continuous delivery, we have more focus on clear identification of issues through our monitoring tools, and ensuring any change with an issue can be turned off with feature toggles. In order to easily identify and therefore resolve bugs we ensure that all changes have metrics associated with them.
The primary tools we use for observability are New Relic, Librato, Bugsnag and Pagerduty. These tools have given us fine-grained details on various metrics and the details we need to quickly fix issues. We also set up alerting on thresholds crossed (such as background job queue size), metrics missing (heartbeats), or large average values (database load spikes). When issues do arise, we are quickly alerted and can be begin investigating within minutes.
We plan to write further on the observability stack at Handshake. In summary: in the rare case a bug slips through our automated tests, it is very short lived.
What’s Next?
It’s been more than 8 months since we adopted continuous delivery. The high-level results so far:
- Smoother deploys — we rarely see increased error rates and response time stays relatively the same.
- Code reviews are smaller, more focused, and faster to review.
- Our automated test suite remains reliable and fast, partly due to its importance in continuous delivery.
- Engineers are able to ship their changes to production quickly and reliably.
We’re currently exploring the move from Continuous Delivery to Continuous Deployment. Instead of one-click deployments, we’d like to automatically stage and deploy changes as soon as the build passes. Make sure to watch for a follow up post after our transition and for more detailed posts in each of these topics!